The design combines FPGA protocol offload, independent 25G Ethernet channels, direct host-memory transfer, and a scalable IP-core architecture to create a practical platform for high-performance remote storage access.
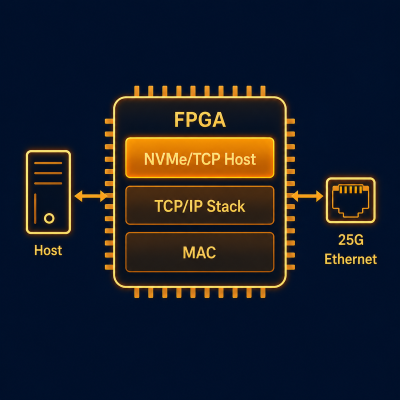
NVMeTCP25G-IP integrates TCP/IP stack and NVMe/TCP host functions in hardware for write/read access to remote NVMe SSDs — with zero CPU involvement in protocol processing.
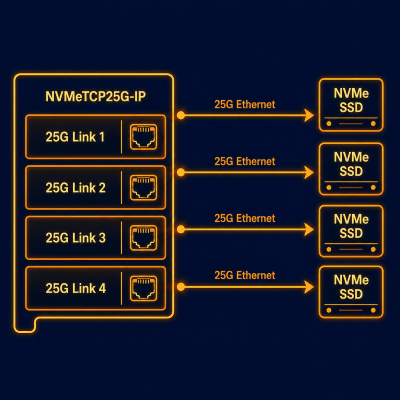
Four 25G Ethernet connections operate simultaneously, allowing the host to access four remote NVMe SSDs in parallel with full per-session bandwidth isolation.
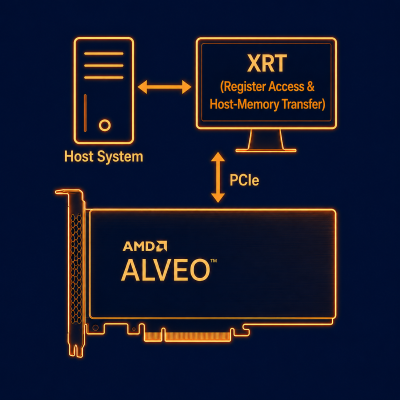
The Alveo card plugs into the host system as a PCIe accelerator, using XRT for register access and high-speed DMA transfers directly into host memory.
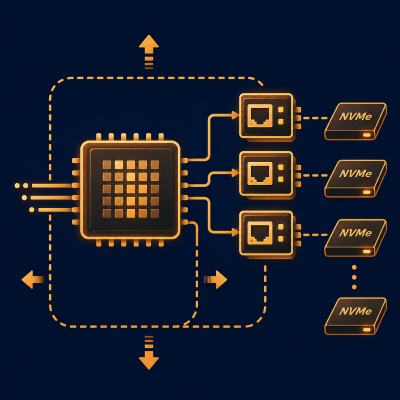
Additional NVMeTCP25G-IP instances can be integrated to expand the number of remote NVMe SSD sessions, scaling storage bandwidth for larger deployments.




