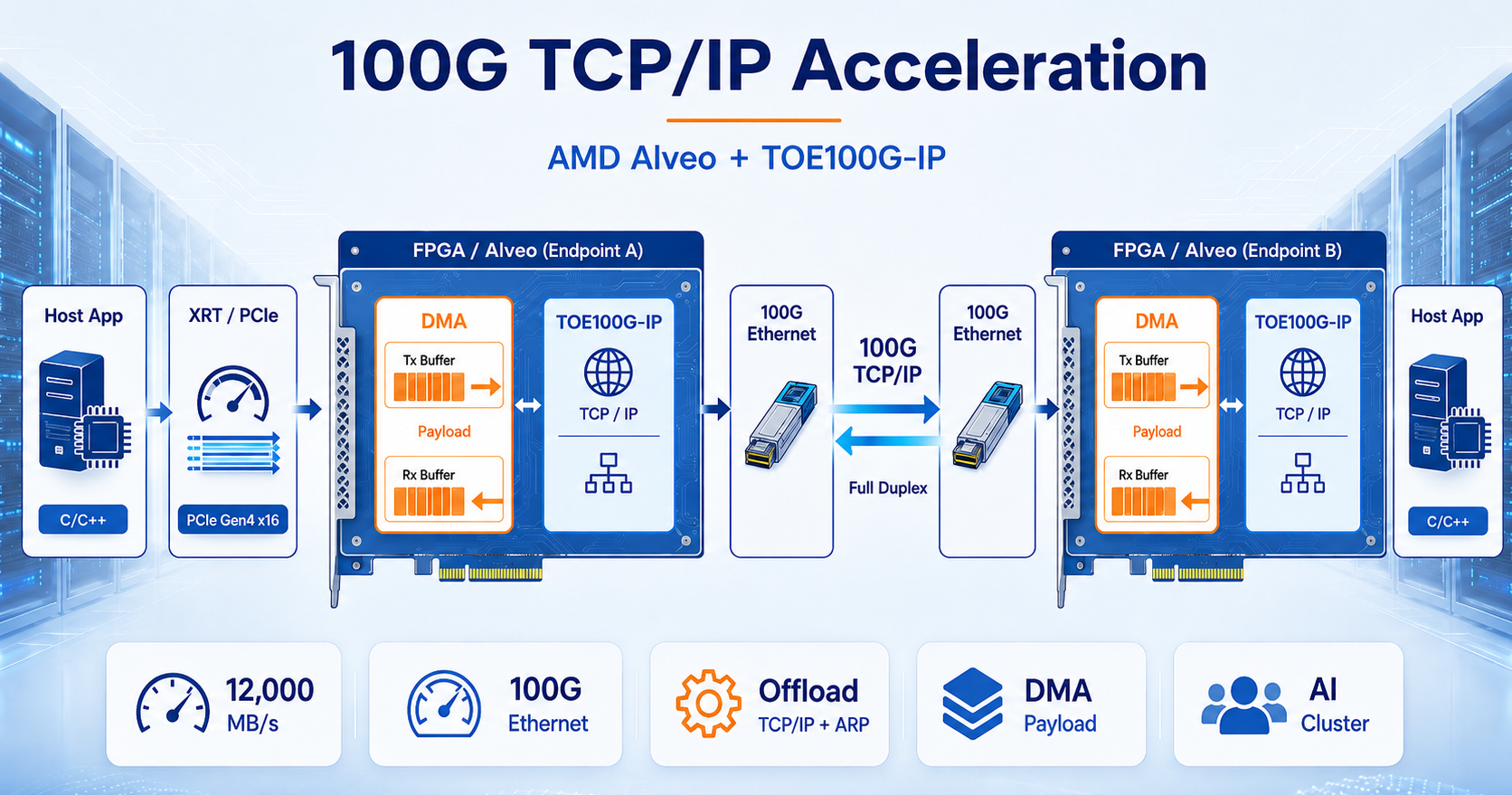
Data Flow: TCP/IP Accelerator by TOE100G-IP
System architecture of 100G TCP/IP acceleration using AMD Alveo and TOE100G-IP. TCP/IP processing is offloaded from host software to FPGA hardware, while payload data moves through DMA buffers over PCIe/XRT. This reduces CPU and OS network-stack overhead, allowing full-duplex FPGA-to-FPGA 100G Ethernet transfer to approach maximum throughput.